En este artículo vamos a intentar adentrarnos ligeramente en el estándar de imágenes JPEG2000 y más específicamente en su Parte 9. Esta parte habla de la arquitectura JPIP (JPEG 2000 Interactive Protocol) que provee de una potencia asombrosa al tratamiento y transmisión de imágenes por las redes.
Su aplicación en el ámbito de la transmisión de imágenes médicas es muy grande puesto que cada vez se utiliza más el envío de imágenes por internet a destinos remotos sin la necesidad de que las imágenes sean DICOM.
Panorama Actual
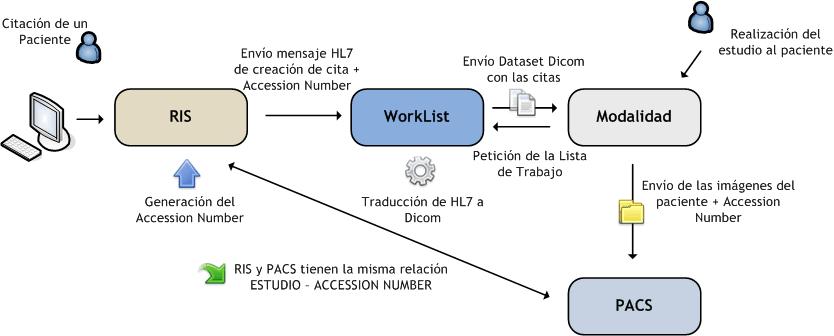
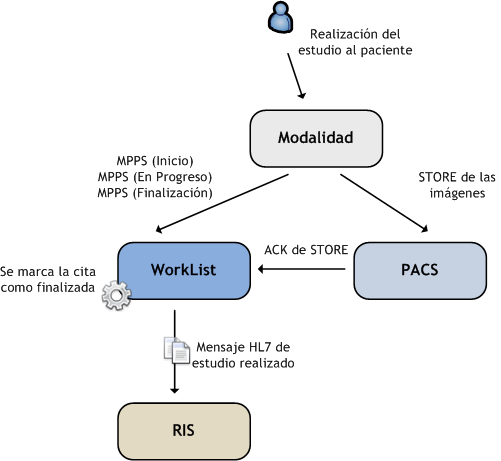
Actualmente, un sistema PACS se puede parecer bastante, en filosofía, al de esquema:

Su aplicación en el ámbito de la transmisión de imágenes médicas es muy grande puesto que cada vez se utiliza más el envío de imágenes por internet a destinos remotos sin la necesidad de que las imágenes sean DICOM.
Panorama Actual
Actualmente, un sistema PACS se puede parecer bastante, en filosofía, al de esquema:

Tenemos un sistema PACS que recibe las imágenes DICOM, que las sirve a los visores diagnósticos y que las envía a su caché web para que se compriman y se sirvan a los usuarios externos que las piden vía HTTP. Las imágenes se comprimen con una determinada calidad y se almacena un puntero a dicha imagen. En estos sistemas, tenemos bastantes copias de una sola imagen, dependiendo de la calidad y de la zona de interés que se haya extraído.
Por otro lado, el envío de las imágenes se realiza de una vez, hasta que no se recibe todo el stream de imagen no se pinta en la pantalla. Dado que las imágenes médicas son cada vez más pesadas y se demanda una mayor calidad (y un control de la calidad) en las imágenes enviadas por internet, el panorama se vuelve cada vez más complicado. A su vez, el informado de imágenes de forma remota y externa a los centros productores es cada vez más común en muchos lugares del mundo, por lo que el tráfico de imágenes será cada vez mayor.
Con esta perspectiva, vamos a ver qué nos ofrece JPIP.
¿Qué nos ofrece JPIP?
Con JPIP podemos implementar sistemas de transmisión de imágenes mucho más eficientes y orientados a la transmisión gradual. JPIP se basa en una arquitectura de servidor que recibe las peticiones de los clientes de diferentes maneras. Lo que más nos interesa en este artículo, es que puede recibir las peticiones y encapsular los mensajes en HTTP. Las ventajas más significativas que nos ofrece JPIP son:
¿Cómo funciona JPIP?
JPIP utiliza dos modos de streaming: JPT-stream y JPP-stream. En los dos modos, la imagen JPEG2000 del servidor es particionada en elementos pequeños llamados "databins". Una imagen JPEG2000 puede ser completamente dividida en "databins" y luego reconstruida en el cliente. Cada "databin" se identifica de manera unívoca y tiene un lugar específico en la imagen.
El cliente JPIP recibe "databins" parciales o completos en respesta a peticiones al servidor JPIP. El decodificador JPEG2000 reconstruirá cada "databin" y se podrá pintar en la interfaz de usuario en su ubicación asignada, mientras se reciben datos del servidor.
El esquema siguiente muestra una arquitectura básica de servidor y cliente JPIP:

Las peticiones llegan al servidor, que busca las imágenes, las procesa según los parámetros recibidos por el usuario y va enviando la información al cliente. El cliente guardará la imagen en su caché local (en caso que la tenga), decodificará la información enviada por el servidor y la mostrará de manera conveniente al usuario.
Parámetros del Cliente:
Una de las características más potentes de JPIP, es la capacidad de enviar en las peticiones GET o POST, parámetros que el servidor intermedio JPIP procesa. Estos parámetros se dividen en 9 grupos:
El potencial que nos ofrece JPIP para el manejo y transmisión de imágenes por internet es muy grande. En este artículo hemos visto un pequeño esbozo de lo que podemos llegar a conseguir, pero las posibilidades son grandísimas. El lado negativo es que aumenta la complejidad de nuestros sistemas y la forma de desarrollarlos, pero el premio, creo que merece la pena.
Algunos enlaces relacionados con JPIP y de los que he sacado la información son:
Página Oficial de JPEG: JPEG2000 Parte 9
Documento Oficial de JPIP: JPIP: Interactivity Tools, APIs and Protocols.
Servidor JPIP de Demo de Pegasus Imaging Corporation: Demo
Espero que os haya gustado el artículo sobre JPIP ya que el tema es muy interesante y, como he dicho, abre un mundo de posibilidades en la transmisión de imágenes médicas (y no médicas) por internet.
Por otro lado, el envío de las imágenes se realiza de una vez, hasta que no se recibe todo el stream de imagen no se pinta en la pantalla. Dado que las imágenes médicas son cada vez más pesadas y se demanda una mayor calidad (y un control de la calidad) en las imágenes enviadas por internet, el panorama se vuelve cada vez más complicado. A su vez, el informado de imágenes de forma remota y externa a los centros productores es cada vez más común en muchos lugares del mundo, por lo que el tráfico de imágenes será cada vez mayor.
Con esta perspectiva, vamos a ver qué nos ofrece JPIP.
¿Qué nos ofrece JPIP?
Con JPIP podemos implementar sistemas de transmisión de imágenes mucho más eficientes y orientados a la transmisión gradual. JPIP se basa en una arquitectura de servidor que recibe las peticiones de los clientes de diferentes maneras. Lo que más nos interesa en este artículo, es que puede recibir las peticiones y encapsular los mensajes en HTTP. Las ventajas más significativas que nos ofrece JPIP son:
- Envío progresivo de datos autocontenidos de la imagen que se pueden mostrar mientras se reciben el resto. Esto permite el envío de imágenes de mucho peso de forma progresiva.
- Acceso por parte del cliente a metadatos de la imagen, permitiendo personalizar dinámicamente lo que se quiere obtener y cómo se quiere obtener (roi, calidad, sesión, canal, tipo de envío, etc.)
- Estandarización en la arquitectura y las peticiones, permitiendo crear servidores y/o clientes independientes del fabricante.
- Posibilidad de eliminación de copias de la imagen, puesto que las imágenes comprimidas, las miniaturas, las ROI, se generan dinámicamente en base a la petición recibida por el cliente.
¿Cómo funciona JPIP?
JPIP utiliza dos modos de streaming: JPT-stream y JPP-stream. En los dos modos, la imagen JPEG2000 del servidor es particionada en elementos pequeños llamados "databins". Una imagen JPEG2000 puede ser completamente dividida en "databins" y luego reconstruida en el cliente. Cada "databin" se identifica de manera unívoca y tiene un lugar específico en la imagen.
El cliente JPIP recibe "databins" parciales o completos en respesta a peticiones al servidor JPIP. El decodificador JPEG2000 reconstruirá cada "databin" y se podrá pintar en la interfaz de usuario en su ubicación asignada, mientras se reciben datos del servidor.
El esquema siguiente muestra una arquitectura básica de servidor y cliente JPIP:

Las peticiones llegan al servidor, que busca las imágenes, las procesa según los parámetros recibidos por el usuario y va enviando la información al cliente. El cliente guardará la imagen en su caché local (en caso que la tenga), decodificará la información enviada por el servidor y la mostrará de manera conveniente al usuario.
Parámetros del Cliente:
Una de las características más potentes de JPIP, es la capacidad de enviar en las peticiones GET o POST, parámetros que el servidor intermedio JPIP procesa. Estos parámetros se dividen en 9 grupos:
- Campos de identificación del objetivo: donde elegimos la imagen o imágenes que queremos pedir al servidor.
- Campos de manejo de la sesión y el canal: donde definimos cómo va a ser la transmisión, el protocolo, las características de la sesión y los canales. También podremos enviar mensajes de cierre de canal.
- Campos de petición de la ventana de imagen: Acceso a una porción de la imagen JPEG2000, en base a la cuadrícula. Se le pasarán parámetros como size, offset,... que determinen con exactitud la parte de la imagen a la que queremos acceder. En este grupo también se definirá la velocidad de transmisión de los datos, las capas que se desean visualizar, las ROIs (acceso por nombre a una zona), etc.
- Campos de metadatos: acceso a metadatos definidos para la imagen.
- Campos de limitación de datos: en este grupo se especificarán cuantos datos se desean recibir del servidor para la petición especificando dos parámetros: calidad y el tamaño máximo de respuesta.
- Campos de control del servidor: se detallarán parámetros del tipo de imagen a recibir (JPP, JPT o raw), si el servidor debe esperar a terminar un mensaje para enviar otro, ...
- Campos de manejo de la caché: parámetros relacionados con el manejo del cache-model del servidor dependiendo del modo en que gestiona el estado de las sesiones.
- Campos de Upload de imágenes: cuando un cliente realiza un upload de una imagen o metadato, utilizará estos campos, especificando el tipo de envío.
- Campos de capacidades del cliente y preferencias: Se especificarán en estos campos las capacidades funcionales del cliente y las preferencias a la hora de la recepción de la información.
El potencial que nos ofrece JPIP para el manejo y transmisión de imágenes por internet es muy grande. En este artículo hemos visto un pequeño esbozo de lo que podemos llegar a conseguir, pero las posibilidades son grandísimas. El lado negativo es que aumenta la complejidad de nuestros sistemas y la forma de desarrollarlos, pero el premio, creo que merece la pena.
Algunos enlaces relacionados con JPIP y de los que he sacado la información son:
Página Oficial de JPEG: JPEG2000 Parte 9
Documento Oficial de JPIP: JPIP: Interactivity Tools, APIs and Protocols.
Servidor JPIP de Demo de Pegasus Imaging Corporation: Demo
Espero que os haya gustado el artículo sobre JPIP ya que el tema es muy interesante y, como he dicho, abre un mundo de posibilidades en la transmisión de imágenes médicas (y no médicas) por internet.













{kind=link}
{kind=link}